8090 Hackathon: From Black Box to Interpretable Box
“Wait, we get the business rules? And the interviews? This isn’t your usual Kaggle hackathon.”
On Kaggle, you mostly care about the data. You never get transcripts of people discussing the data. You just train an ML model and try to beat the competition. Maybe you can gather one or two insights from external context, but that’s pretty much it. It might help with pre-processing, but modeling is just a battle between those beasts: XGBoost, LightGBM, CatBoost, Transformers, etc.
But here, things are different. The task is to create a perfect replica of an existing rule-based system. An ML model can’t do that—only deterministic code can. We need Python code at the end, not just the weights of a big model with limited interpretability.
The system takes 3 inputs: trip_duration_days, miles_traveled, total_receipts_amount, and outputs a single number: the reimbursement amount.
| Input | Value |
|---|---|
| trip_duration_days | 3 |
| miles_traveled | 93 |
| total_receipts_amount | 1.42 |
| Output | 364.51 |
Intuitively, I decided not to spend my Saturday training another ML model—I already do that enough at work. Instead, I tried to reverse engineer the existing system and predict understandable business rules from the interview transcripts. And I think that’s better, even if you scored lower:
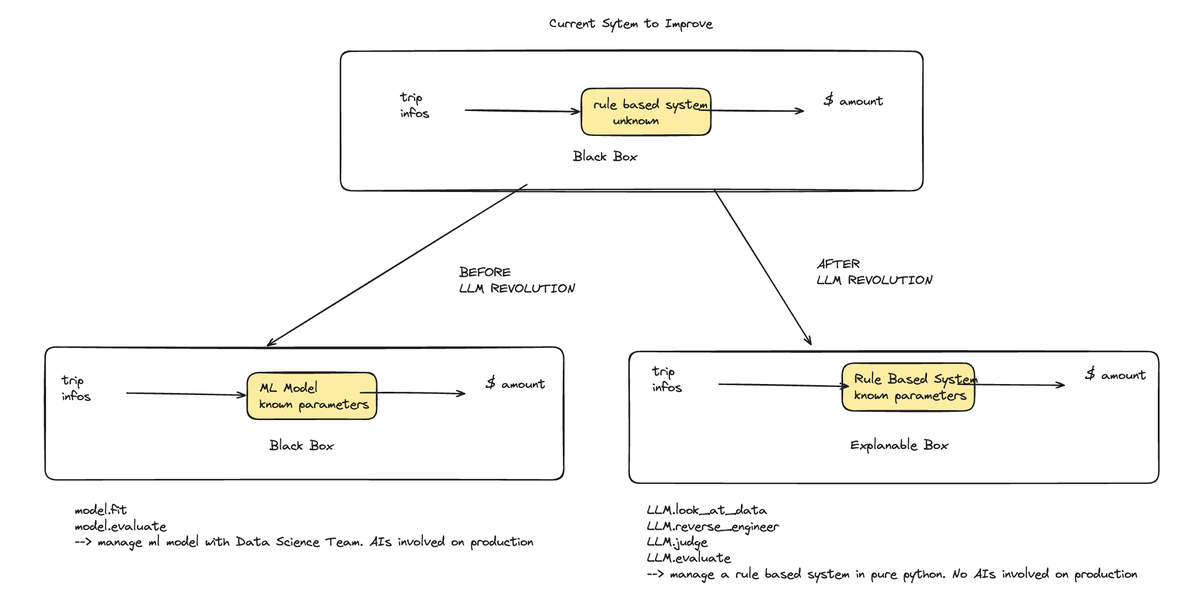
The Old Model: Black Box ML
In the old approach, you’d just train a model on whatever dataset you were given, crank out predictions, and cross your fingers. There was no real understanding of what was happening under the hood—the system was a total black box.
Your main concern was overfitting: would your model generalize, or just memorize quirks in the data? You rarely knew if predictions made sense—only if they scored well. Some libraries, like SHAP, help with interpretability. But that’s about as much as you get.
Human-Readable Software >> Stochastic Software
Software with lots of unknown business rules and ML models are both stochastic from the user’s perspective. There are some answers no one can really explain.
But if your software is readable line by line, you’re in a much better position. In high-stakes scenarios—like lawsuits about loan rejection—that level of clarity can be the difference between winning and losing.
LLMs Can Leverage Kevin to Reverse-Engineer the Problem; Standard ML Cannot
From the interview transcripts:
Kevin: “I did k-means on all my data. The clusters match different reimbursement rules. Now I can predict within 15%.”
Kevin from procurement has a lot of insights about the data. First, he claims there are 6 distinct clusters, and you can find them with k-means clustering (k=6). An LLM can read that and generate Python code to do exactly that. Then he describes the business rules for each cluster. An LLM can determine the highest degree of the polynomial equation needed to describe all the business rules, and generate Python code for that, on top of the k-means classification.
-> LLMs can get the full context of the problem, while standard ML cannot.
My Takeaways
First, this hackathon was wild: you could just spin up an event like this using X, no $100k platform fee to get a smart crowd.
My personal takeways and things I will think about next time:
- This hackathon is about understanding, not just predicting.
- You now have the tools to explain your solution, not just optimize a score.
- Maybe training a black box ML model is still super useful: you could artificially increase your number of datapoints and it can be easier to find hard-coded rules than when staying with the 1000 rows of data (much easier to find the boundaries for the k-means!)
- LLM to generate code, deploy generated code on production is probably the safest workflow right now